TOC
编译基础
抽象语法树
抽象语法树(Abstract Syntax Tree, AST),是源代码语法结构的一种抽象表示,它是用树状的方式表示编程语言的语法结构(除去源代码中空格、分号等不重要的一些字符)。抽象语法树中的每一个节点都表示源代码中的一个元素,每一颗子树都表示一个语法元素。 eg: 表达式 1 * 2 + 3 编译器的语法分析阶段会生成如下所示的AST:
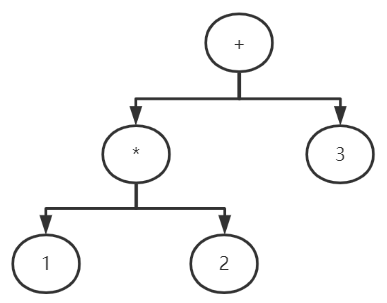
编译器执行完语法分析之后会生成一个AST,这个AST会辅助编译器进行语义分析,用来确定语法正确的程序是否存在一些类型不匹配的问题。
静态单赋值
静态单赋值(Static Single Assignment,SSA)是中间代码的特性,主要作用是对代码进行优化,如果中间代码具有静态单赋值的特性,那么每个变量就只会被赋值一次。 eg:
x := 1
x := 2
y := x
经过简单分析,我们可以发现上述代码中x := 1 并不会有任何作用。下面是具有SSA特性的中间代码,我么可以看到y_1和x_1是没有任何关系的,所以在机器码生成时就可以省区x := 1的复制,通过减少需要执行的指令优化这段代码。
x_1 := 1
x_2 := 2
y_1 := x_2
指令集
指令集架构是计算机的抽象模型,在很多时候也被称作架构或者计算机架构,它是计算机软件和硬件之间的接口和桥梁;每一个指令集架构都定义了支持的数据结构、寄存器、管理主内存的硬件支持(例如内存一致、地址模型和虚拟内存)、支持的指令集和 IO 模型,它的引入其实就在软件和硬件之间引入了一个抽象层,让同一个二进制文件能够在不同版本的硬件上运行。
不同的机器可能使用不同的指令集,我们可以输入 uname -m 获取当前机器的硬件信息。不同的处理器使用了不同的架构和机器语言(amd、arm等),很多编程语言为了在不同的机器上运行需要将源代码根据架构翻译成不同的机器代码。
$ uname -m
x86_64
复杂指令集计算机(CISC)和精简指令集计算机(RISC)是两种遵循不同设计理念的指令集,两者区别:
- 复杂指令集:通过增加指令的类型减少需要执行的指令数;
- 精简指令集:使用更少的指令类型完成目标的计算任务;
早期的 CPU 为了减少机器语言指令的数量一般使用复杂指令集完成计算任务,两者并没有绝对的优劣,殊途同归。
编译原理
根据阶段工作任务不同,编译器分为前端和后端。编译器前端一般承担着词法分析、语法分析、类型检查和中间代码生成几部分工作,而编译器后端主要负责目标代码的生成和优化,也就是将中间代码翻译成目标机器能够运行的二进制机器码。
Go语言编译器的源代码在src/cmd/compile目录下。Go的编译器在逻辑上分为四个阶段:词法和语法分析、类型检查、AST转换、通用SSA生成和最后的机器代码生成。
词法和语法分析
所有的编译过程都是从解析代码的源文件开始,词法分析的作用就是解析源代码文件,它将文件中的字符串序列转换成Token序列,方便后面的处理和解析。我们一般把执行词法分析的程序称为词法解析器(lexer)。
语法分析的输入就是词法分析器(lexer)输出的Token序列,语法分析器会按照顺序解析Token序列,该过程会将词法分析生成的Token按照编程语言定义好的文法(Grammar)自上而下或者自下而上的规约,每一个Go的源文件最终会被归纳成一个SourceFile结构;
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
词法分析会返回一个不包含空格、换行等字符的 Token 序列,例如:package, json, import, (, io, ), …,而语法分析会把 Token 序列转换成有意义的结构体,即语法树:
"json.go": SourceFile {
PackageName: "json",
ImportDecl: []Import{
"io",
},
TopLevelDecl: ...
}
Token 到上述抽象语法树(AST)的转换过程会用到语法解析器,每一个 AST 都对应着一个单独的 Go 语言文件,这个抽象语法树中包括当前文件属于的包名、定义的常量、结构体和函数等。语法解析的过程中发生的任何语法错误都会被语法解析器发现并将消息打印到标准输出上,整个编译过程也会随着错误的出现而被中止。
类型检查
当拿到一组文件的抽象语法树之后,Go 语言的编译器会对语法树中定义和使用的类型进行检查,类型检查会按照以下的顺序分别验证和处理不同类型的节点:
- 常量及类型、函数名及类型;
- 变量的赋值和初始化;
- 函数和闭包的主体;
- 哈希键值对的类型;
- 导入函数体;
- 外部的声明;
通过对整棵抽象语法树的遍历,每个节点上都会对当前子树的类型进行验证,以保证节点不存在类型错误,所有的类型错误和不匹配都会在这一个阶段被暴露出来,其中包括:结构体对接口的实现。
类型检查阶段不止会对节点的类型进行验证,还会展开和改写一些内建的函数、关键字,例如 make 关键字在这个阶段会根据子树的结构被替换成 runtime.makeslice 、 runtime.makechan、 runtime.makemap函数。
中间代码生成
中间代码是编译器或者虚拟机使用的语言,它可以来帮助我们分析计算机程序。在编译过程中,编译器会在将源代码转换到机器码的过程中,先把源代码转换成一种中间的表示形式,即中间代码。
当源文件被转换成了抽象语法树、整棵树的语法被进行解析并进行类型检查之后,就可以认为当前文件中的代码不存在语法错误和类型错误的问题了,Go 语言的编译器就会将输入的抽象语法树转换成中间代码。
在类型检查之后,编译器会通过cmd/compile/internal/gc.compileFunctions编译整个 Go 语言项目中的全部函数,这些函数会在一个编译队列中等待多个Goroutine消费,并发执行的Goroutine会将所有函数对应的抽象语法树转换成中间代码。由于 Go 语言编译器的中间代码使用了 SSA 的特性,所以在这一阶段我们能够分析出代码中的无用变量和片段并对代码进行优化。
为什么不是直接将源代码翻译成机器码?
我们可以直接将源代码翻译成目标语言,这种看起来可行的办法实际上有很多问题,其中最主要的是:它忽略了编译器面对的复杂场景,很多编译器需要将源代码翻译成多种机器码,直接翻译高级编程语言相对比较困难。将编程语言到机器码的过程拆成中间代码生成和机器码生成两个简单步骤可以简化该问题,中间代码是一种更接近机器语言的表示形式,对中间代码的优化和分析相比直接分析高级编程语言更容易。
机器码生成
在主程序运行的最后,编译器会将顶层的函数编译成中间代码并根据目标的 CPU 架构生成机器码,不过在这一阶段也有可能会再次对外部依赖进行类型检查以验证其正确性。Go 语言源代码的 src/cmd/compile/internal 目录中包含了很多机器码生成相关的包,不同类型的 CPU 分别使用了不同的包生成机器码,其中包括 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm等。经过编译后的 Go 语言,就可以在几乎全部的主流机器上运行了。
编译器入口
Go 语言的编译器入口在 src/cmd/compile/internal/gc/main.go 文件中,其中 600 多行的 cmd/compile/internal/gc.Main 就是 Go 语言编译器的主程序,该函数会先获取命令行传入的参数并更新编译选项和配置,随后会调用 cmd/compile/internal/gc.parseFiles 对输入的文件进行词法与语法分析得到对应的抽象语法树。
看代码去了。。。
comments powered by Disqus